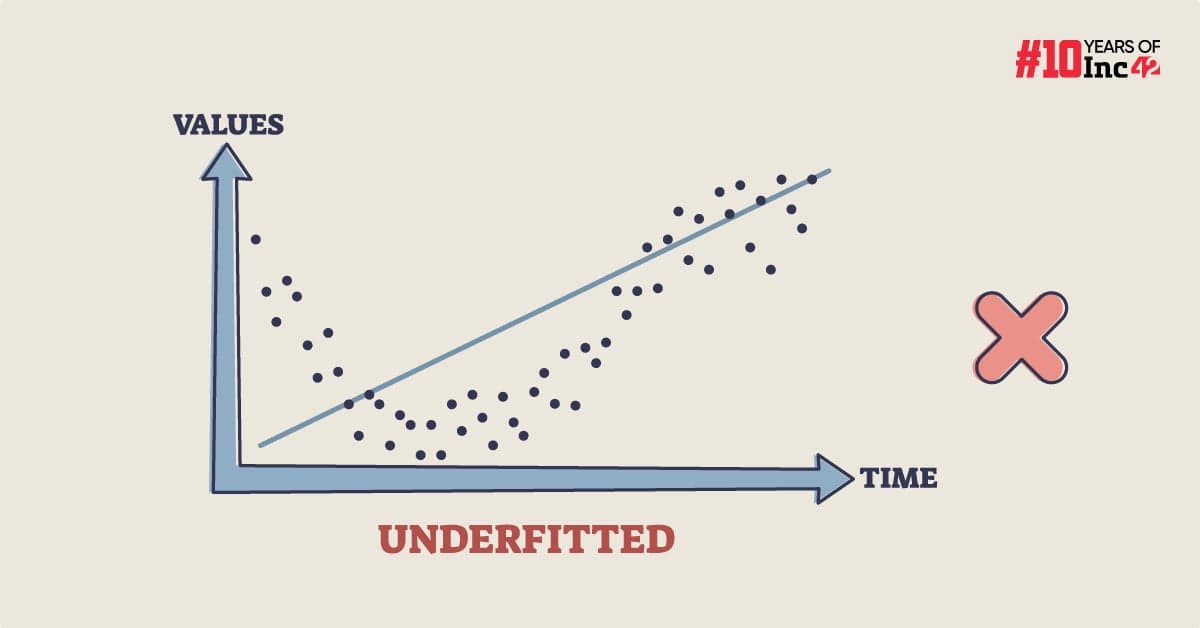
What Is Underfitting?
Underfitting refers to a scenario in machine learning where a model fails to capture the underlying patterns within the data effectively. This results in inaccurate predictions on both the training data, the data used to train the model, and new, unseen data.
Why Does Underfitting Happen?
Underfitting in machine learning arises due to several reasons, often stemming from an oversimplified model or limitations in the training process. Here’s a deeper dive into the causes:
Model Complexity
- Simple Model Choice: Opting for a model that is inherently incapable of capturing intricate relationships within the data leads to underfitting. For instance, using linear regression as a model for a problem with non-linear data would not model the data effectively.
- Limited Training Time: If a complex model isn’t trained for a sufficient duration, it might not grasp the nuances of the data. Imagine learning a new language — limited practice restricts your ability to understand complex sentence structures.
Data Issues
- Insufficient Training Data: When the model is trained on a small dataset, it lacks the necessary examples to learn the underlying patterns effectively. This is akin to having a limited vocabulary hindering your ability to express yourself comprehensively.
- Irrelevant Or Noisy Data: Training data containing irrelevant features or excessive noise (errors or outliers) confuses the model and hinders its ability to learn the true relationships. Think of studying with inaccurate information; it leads to a skewed understanding.
- Regularisation: Regularisation techniques are used to prevent overfitting, but excessive application can restrict the model’s flexibility too much. This can prevent it from capturing even the essential patterns in the data.
What Are The Symptoms Of Underfitting?
Underfitting manifests through various symptoms that indicate the model’s inability to learn effectively from the data. Here are some key signs to watch out for:
- High Training & Testing Error: The model performs poorly on both the training data it was trained on and the unseen testing data. This signifies that the model hasn’t learned the underlying patterns well enough to make accurate predictions on any data.
- Stagnant Learning Curve: Plotting the training error against the number of training iterations (epochs) reveals a characteristic pattern. In an underfitting scenario, the error might plateau or even slightly increase as the model continues training. This indicates the model isn’t effectively utilising the additional training data.
- High Bias: Underfitting often results in high bias, meaning the model consistently underestimates the relationship between the input features and the target variable. This leads to systematic errors in the predictions.
- Simple Model Behaviour: The model’s predictions might appear overly simplistic, failing to capture the nuances present in the data. For instance, a model predicting constant values for all data points signifies significant underfitting.
- Ineffectiveness Of Regularisation Techniques: Techniques like L1 or L2 regularisation are employed to prevent overfitting. However, in underfitting cases, applying these techniques might not have a significant impact on the model’s performance, as the model already has a limited capacity to learn complex patterns.
How Can Underfitting Be Fixed?
Underfitting can be tackled through various approaches. Here are some effective strategies:
Increasing Model Complexity:
- Choosing a More Complex Model Architecture: Opt for models with a higher capacity to learn intricate patterns. This could involve:
- Shifting from linear models to non-linear models like decision trees, random forests, or neural networks.
- Increasing the number of layers or neurons in a neural network architecture.
- Training For A Longer Duration: Provide the model with more training iterations (epochs) to allow it to learn the underlying data patterns effectively.
Addressing Data Issues:
- Gather More Data: If possible, collect additional relevant data points to enrich the training set and provide the model with a wider range of examples.
- Improve Data Quality: Address issues like missing values, outliers, and inconsistencies within the data to ensure the model is learning from clean and reliable information.
Feature Engineering:
- Crafting New Features: Derive new features from existing ones that might be more informative and better capture the relationships relevant to the task.
- Feature Selection: Choose a suitable subset of features that are most relevant to the prediction task. This can prevent the model from being overwhelmed by irrelevant information.
Regularisation Tuning:
- Fine-Tuning Regularisation Parameters: Techniques like L1 and L2 regularisation help prevent overfitting but can hinder learning if applied excessively. Adjust the regularisation parameters to strike a balance between preventing overfitting and allowing the model to learn effectively.
Addressing Other Factors:
- Hyperparameter Tuning: Experiment with different hyperparameters of the model (for example, learning rate and number of hidden layers) to find the optimal configuration that facilitates better learning.
- Early Stopping: Implement early stopping techniques to prevent the model from overtraining on the training data. This involves stopping the training process once the validation error starts to increase.







